Wśród memicznych obrazków krążących po internecie poczesne miejsce zajmują fotki z serii „you had one job” czyli „miałeś tę jedną rzecz do zrobienia”. Na fotkach widzimy spektakularne przykłady ludzkiej niekompetencji, np. schody, którymi wykonawca nie trafił w drzwi wejściowe, namalowany na jezdni przed skrzyżowaniem napis SOTP albo betonowy balkon przebity przez latarnię uliczną.
Te właśnie obrazki nasunęły mi się na myśl, gdy dostrzegłem jeden z ciekawszych błędów Systemu Losowego Przydziału Spraw. Panowie i panie, mieliście jedną rzecz do zrobienia. Wyznaczyć pulę nazwisk do losowania i dokonać losowania. Tylko tyle i aż tyle. A jak wyszło, zobaczymy poniżej.
Zdradliwa matematyka
Czasem w losowaniu sprawy bierze udział tylko dwójka sędziów. Dzieje się tak w małych wydziałach, ale może zdarzyć się gdziekolwiek, jeśli spiętrzeniu ulegną nieobecności lub wyłączenia ze sprawy.
Gdy w puli są tylko dwa nazwiska, uruchamiany jest specjalny mechanizm mający na celu balansowanie wyników losowań. Sędzia o mniejszym wskaźniku obciążenia pojawia się w puli dwukrotnie. Losowość zostaje zachowana, ale rozkład prawdopodobieństwa faworyzuje sędziego któremu należy przydzielić więcej spraw.
Jak wiemy z artykułu pt. „Koszt sprawy”, sędziowie pełniący niektóre funkcje mogą otrzymywać nawet 10x mniej spraw, niż „zwykły” sędzia. Odpowiada za to tzw. wskaźnik udziału w losowaniach. I tu pojawia się problem, bo w serii losowań dwuosobowych (z podwojonym nazwiskiem) największym możliwym do wyprodukowania niezbalansowaniem jest 33,3% do 66,6%. A potrzeba 9,1% do 90,9%.
Algorytm losowania zawiera więc dodatkowy przypadek szczególny - jeśli iloraz wskaźników udziału (nie wskaźnika obciążenia!) przekracza 2, zwielokrotnianiu ulega sędzia z większym wskaźnikiem udziału. Zależnie od wartości ilorazu, zwielokrotnienie może być nawet ośmiokrotne - z kontekstu wynika, że wraz z pierwotnym wpisem będzie to dziewięć wystąpień tego samego nazwiska na raporcie z losowania. Oto przykłady takich raportów:

Póki co wszystko wygląda dobrze. Losowań o takiej charakterystyce naliczyłem ponad 100 tysięcy, czyli ani dużo, ani mało. Gdy jednak przeglądałem zwielokrotnione raporty z roku 2022, coś rzuciło mi się w oczy.

Losowania miały być dokonywane spośród wszystkich dziesięciu pozycji, jednak operacja modulo na liczbie losowej obejmowała jedynie… pierwsze cztery pozycje. Zacząłem grzebać głębiej. Co się okazało?
WSZYSTKIE ZWIELOKROTNIONE LOSOWANIA Z ROKU 2022 UWZGLĘDNIAŁY TYLKO PIERWSZE 4 LOSOWANE POZYCJE!
Co mówi dokumentacja?
Zajrzyjmy po raz setny do dokumentu „Algorytm na podstawie dokumentacji analitycznej v.1.16.1”. Oszczędzę czytelnikom zrzutów ekranu, przejdziemy po krokach 15-18 na przykładzie naszego losowania z ilustracji powyżej. W dokumencie są to strony 18 i 19.
- krok 15 - tworzymy listę sędziów biorących udział w losowaniu, mamy w niej dwóch sędziów
- krok 16 - ustalamy rozmiar puli na 2
- krok R17a - rozmiar puli na pewno rośnie do 10, z opisu nie wynika, czy lista sędziów ma być wzbogacona o ośmiu zwielokrotnionych, wirtualnych kandydatów
- krok R17c - algorytm kroku R17c odwołuje się rekursywnie do algorytmu R17c, wszystkim czytelnikom przepełnia się stos
- krok R18 - z listy dwóch lub dziesięciu sędziów bierzemy pierwszych dziesięciu sędziów, po czym dodajemy zwielokrotnionych wirtualnych kandydatów
Co można powiedzieć o takiej dokumentacji? Na pewno nie jest czytelna. Sprzeczność opisu z diagramem przepływu funkcji R17a wskazywałem w artykule „Jak SLPS wylicza wskaźniki obciążenia”. Wydaje się jednak, że - mimo doboru niejasnego słownictwa - sam sposób wyznaczania rozmiaru puli jest w porządku. Zepsuto implementację.
You had one job…
Gdy ktoś przyjrzy się losowaniom z ośmiokrotnym zwielokrotnieniem, to odkryje, że tabela z dziesięcioma wierszami ma jeden z zaledwie dwóch wariantów numeracji:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10
albo
2, 3, 4, 5, 6, 7, 8, 9, 10, 1
Czemu tak? We artykule „O tym, dlaczego System Losowego Przydziału Spraw jest nieprzejrzysty i nierozliczalny” pokazałem, że wylosowana pozycja nie wskazuje wiersza w tabelce, lecz wartość z kolumny „Pozycja” - która zawczasu została już zrandomizowana w sposób pozostający zagadką. Okazuje się jednak - przy czym jest to obserwacja, niepodparta żadną teorią - że zwielokrotnione nazwisko zawsze tworzy spójny blok numeracji, więc nazwisko pojedyncze może dostać numer 1 albo 10.
Spójrzmy na ilustrację poniżej. Wygrać mogą tylko numery 1-4. Nazwiska zduplikowane zawsze są na początku tabeli, nazwisko pojedyncze - na końcu. Wszystkie możliwe warianty numeracji wraz z zaznaczonymi ramką miejscami potencjalnie wygrywającymi widzimy w tabeli.
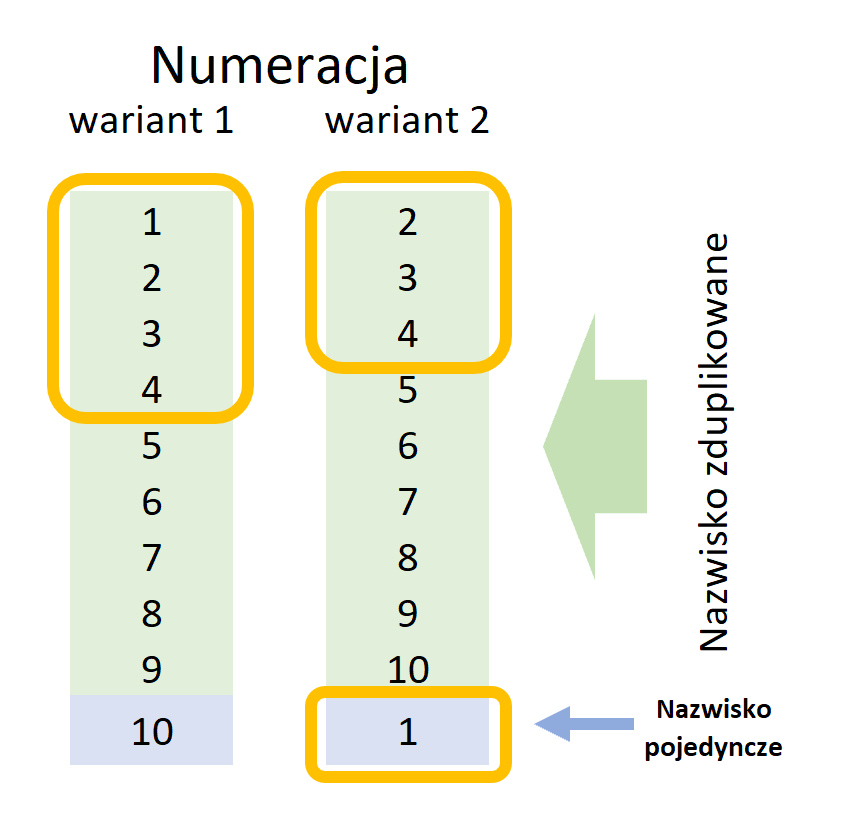
Widzimy, że nazwisko pojedyncze to jedna z ośmiu możliwości wylosowania zwycięzcy, czyli zostanie trafione w 12,5% przypadków. Częściej, niż powinno - oczekiwalibyśmy rozkładu równomiernego dającego 10% szansy.
Mówiąc prościej - jeśli numeracja w tabeli idzie od 1 do 10, to zawsze wygrywa zwielokrotniony kandydat. Jeśli numery w tabelce startują od 2 i kończą się na 1, to zwielokrotniony kandydat wygrywa w 3/4 przypadków.
Jako ćwiczenie dla zainteresowanego czytelnika zostawiamy dowód, że prawidłowe prawdopodobieństwa otrzymamy dla „zwielokrotnionych” losowań dwuosobowych mających 4 i 8 wierszy w tabeli, zaś przy wariantach mających 5, 6, 7, 9 lub 10 wierszy wynik będzie nieprawidłowy.
Podsumowanie
W punktach:
- w przypadku losowań dwuosobowych ze specjalnym zwielokrotnieniem wynikającym z dużej różnicy wskaźnika udziału w losowaniu, do puli losującej powinny trafić wszystkie zdublowane pozycje (np. w powyższych przykładach - wszystkie 10)
- w rzeczywistości losowano pierwsze cztery pozycje
- z powodu błędu programistycznego zamiast rozkładu prawdopodobieństwa dopasowanego do „krotności” zwielokrotnienia, sędzia występujący w tabeli w jednym wierszu ma zawsze 12,5% szans na wygraną
- użycie sprzętowego generatora liczb losowych i obliczanie wartości modulo stanowi jedynie teatrzyk, który nie ma tu żadnego znaczenia
Błąd usunięto w wersji SLPS wdrożonej w marcu 2023. Dodajmy więc tylko w charakterze wisienki na torcie, że kombinacja dwóch sędziów mających wskaźniki udziału wynoszące 10% i 100% powinna skutkować przydziałem spraw w stosunku 9,1% do 90,9%. Naprawiony SLPS nadal tego nie umie.
Niezmiennie zaś - po dziś dzień, we wszystkich losowaniach - użycie w SLPS sprzętowego generatora liczb losowych i obliczanie wartości modulo stanowi jedynie teatrzyk, który nie ma żadnego znaczenia.
Masz pytania lub uwagi do niniejszego tekstu? Napisz!
Tomasz Zieliński